
项目地址:
https://github.com/Plachtaa/seed-vc
整合包下载:
注:可复制链接,手机打开夸克转存
https://pan.quark.cn/s/00056c1a5ef6

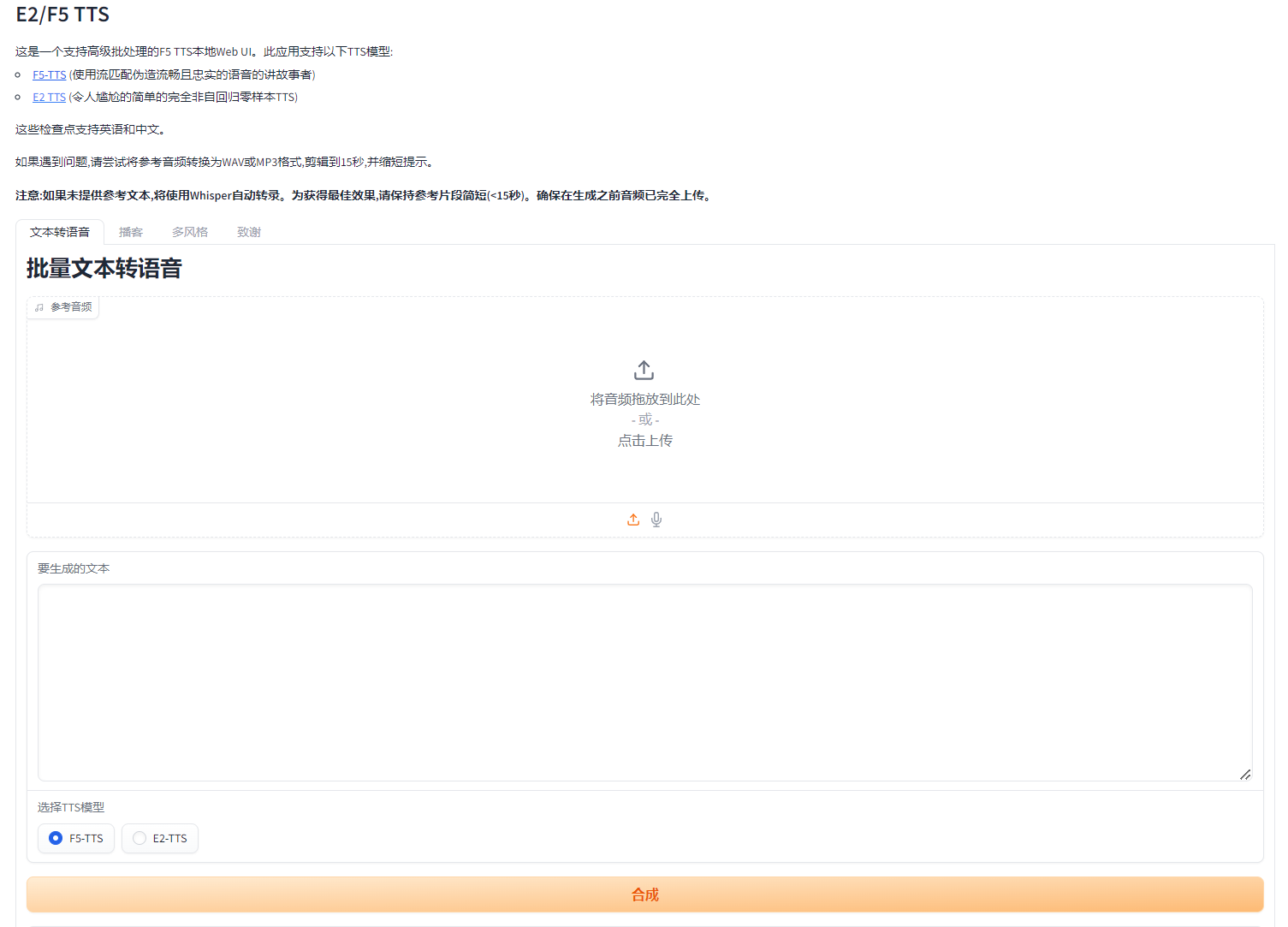
项目简介
目前发布的模型支持 零样本语音转换 🔊 、零样本实时语音转换 🗣️ 和 零样本歌声转换 🎶。无需任何训练,只需1~30秒的参考语音,即可克隆声音。
支持进一步使用自定义数据进行微调,以提高特定说话人的性能,数据需求门槛极低 (每位说话人至少1条语音) ,训练速度极快 (最少100步,在T4上只需2分钟)!
实时语音转换 支持约300ms的算法延迟和约100ms的设备侧延迟,适用于在线会议、游戏和直播。
要查看演示和与之前语音转换模型的比较,请访问的演示页面🌐 和 评估结果📊。
项目部署:
#python 3.10
pip install -r requirements.txt
python app.py
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END








暂无评论内容