
F5-TTS项目地址:https://github.com/SWivid/F5-TTS
F5-TTS汉化整合包:https://pan.quark.cn/s/9754ae0cdbe4
F5-TTS在线demo: https://huggingface.co/spaces/mrfakename/E2-F5-TTS
![图片[1]-F5-TTS语音克隆汉化整合包1016 - 360p.blog-360p.blog](https://360p.blog/wp-content/uploads/2024/10/20241016102840375-image.png)
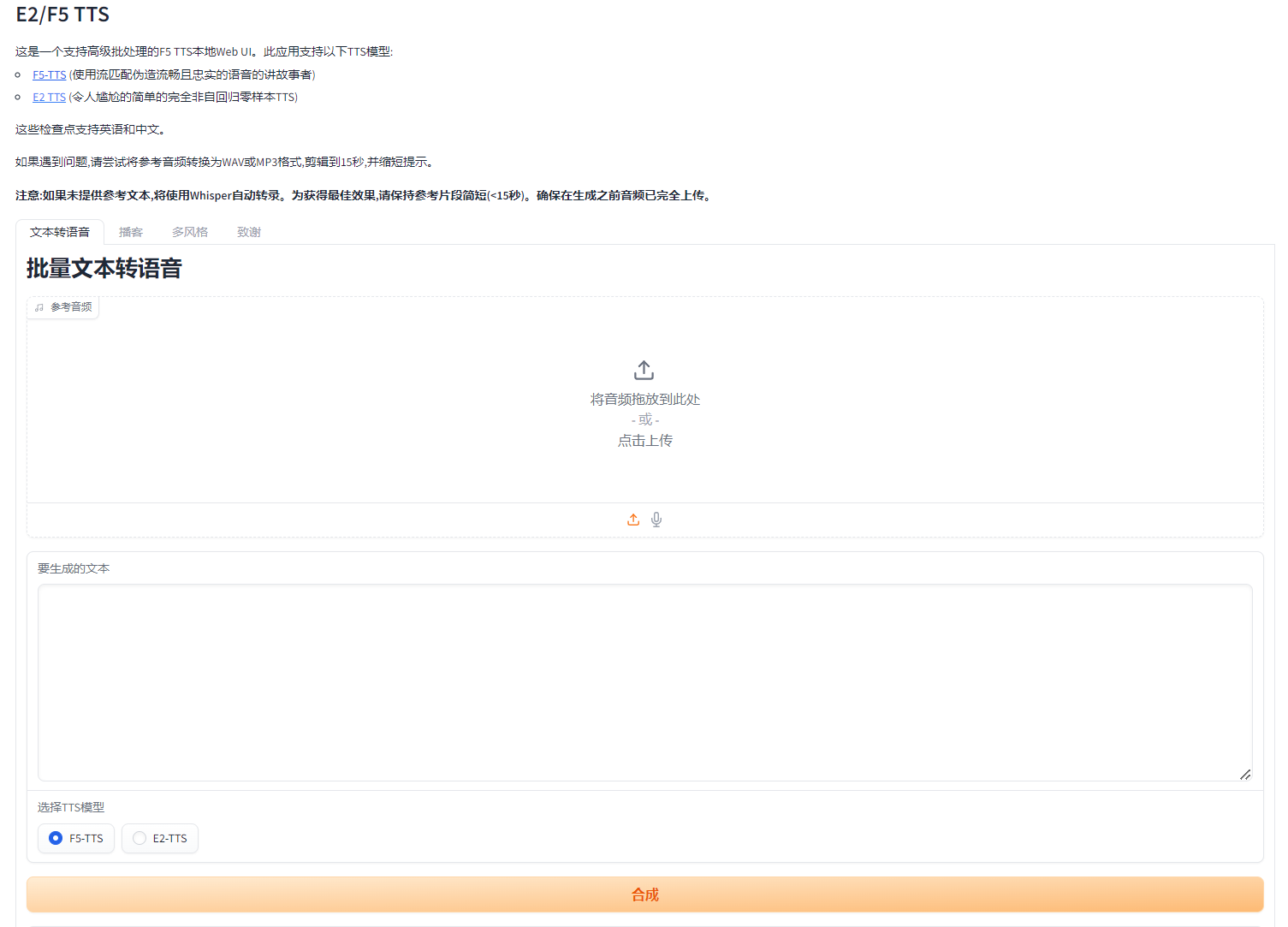
F5-TTS是由上海交通大学开源的一款基于流匹配的全非自回归文本到语音转换系统(Text-to-Speech,TTS)。它以其高效、自然和多语言支持的特点脱颖而出,接近商用水平。以下是F5-TTS的一些关键特性和技术亮点:
- 全非自回归架构:F5-TTS采用全非自回归模型,能够并行处理整个语音合成任务,显著提高了处理速度和效率,实现了实时因素(RTF)0.15的推理速度,远优于当前基于扩散的TTS模型。
- 流匹配技术:F5-TTS中采用了先进的流匹配技术,这是一种基于最优传输路径的方法,用于改进生成模型的学习过程。该技术允许模型更精确地模拟目标数据的分布,从而提高合成语音的自然性和准确性。
- Diffusion Transformer(DiT)的应用:F5-TTS利用了Diffusion Transformer,这是一种结合了扩散模型的Transformer结构,专门用于处理生成任务中的对齐和数据生成问题。DiT可以在保持文本到语音合成高质量的同时,提供更快的响应时间和更低的资源消耗。
- Sway Sampling策略:在推理时,F5-TTS引入了Sway Sampling策略,这是一种新颖的采样方法,用于在模型的流步骤中更有效地选择样本。这种方法可以进一步提升语音生成的自然度和可理解性,同时保持与原始文本的高度一致性。
- 简化的训练流程:相比传统模型,F5-TTS不需要复杂的组件如持续时间预测器、文本编码器或音素对齐模块。这种简化大大降低了模型的复杂性,使得训练过程更快,同时降低了对计算资源的需求。
- 高性能和多语言支持:F5-TTS在公共的100K小时多语言数据集上进行训练,展示了其对多种语言的高自然处理能力。该模型支持无缝的代码切换能力和速度控制,使其在多样化的应用场景中表现出色。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







暂无评论内容