
🚀 阿里云推出Qwen2.5-Turbo模型:长文本处理再创纪录
你有没有想过,一次性阅读完十部小说会是怎样的体验?阿里云最新发布的Qwen2.5-Turbo大语言模型或许可以帮你实现这个梦想。这个令人瞠目结舌的模型拥有高达100万Token的上下文长度。换句话说,它可以轻松应对10部《三体》小说的阅读量、处理150小时的语音转录,甚至消化3万行代码。这种强大的能力让人不禁惊叹科技的飞速发展。
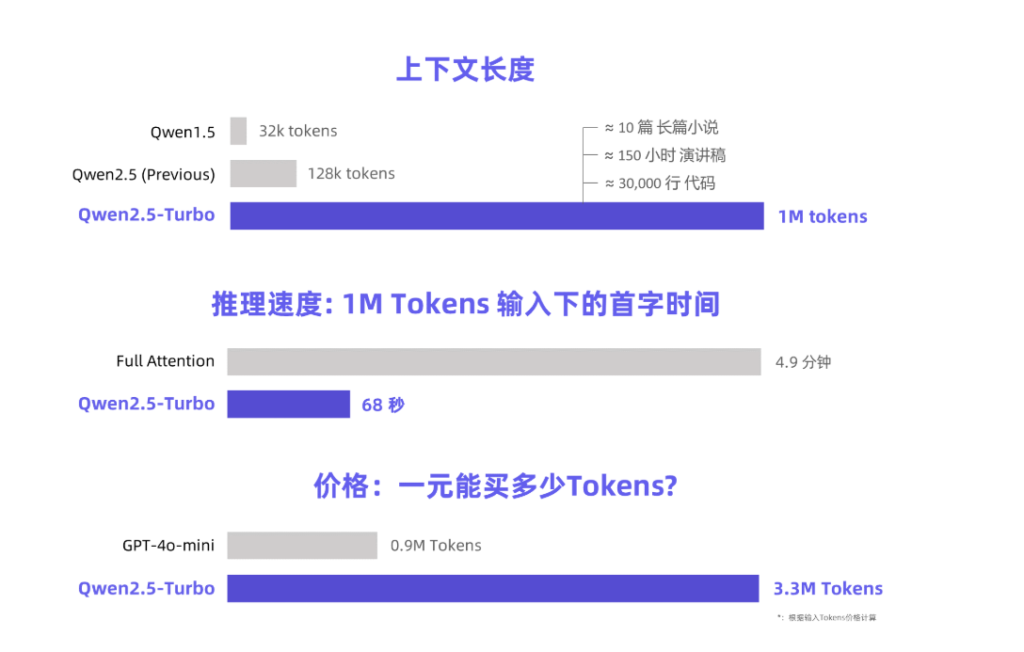
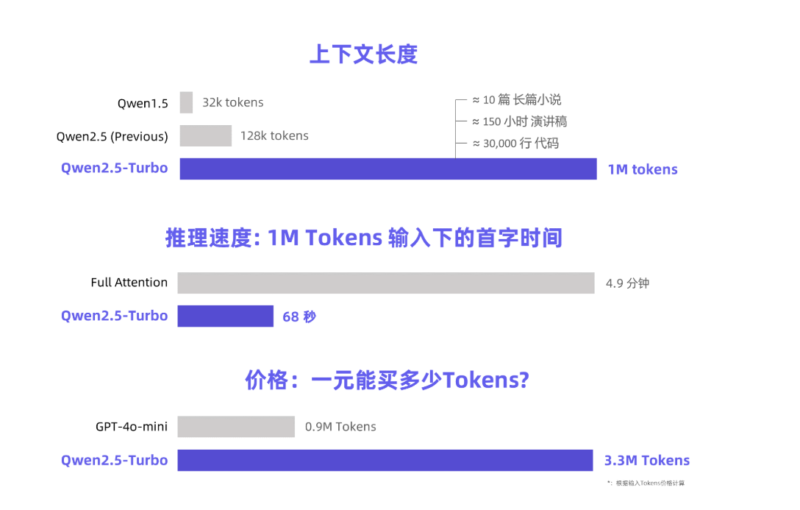
卓越的准确率与速度
在Passkey Retrieval任务中,Qwen2.5-Turbo以100%的准确率笑傲群雄,其长文本理解能力更是超越了同类的GPT-4等知名模型。在RULER长文本基准测试中,它获得了93.1的高分,这一成绩让GPT-4和GLM4-9B-1M稍显逊色,分别得分91.6和89.9。
令人惊喜的是,Qwen2.5-Turbo不仅在长文本中表现优异,在短文本处理上也毫不逊色。采用稀疏注意力机制后,该模型将处理100万Token的时间从4.9分钟锐减至68秒,实现了4.3倍的速度提升。更值得一提的是,处理同样量级的Token费用仅需0.3元人民币,比起GPT-4o-mini来说,性价比优势显著,可以在相同成本下处理更多内容。
模型应用前景广阔
阿里云为这个模型精心设计了一系列演示,展现其在长篇小说深度理解、代码辅助和多篇论文阅读等方面的强大应用。例如,当用户上传包含69万Token的《三体》三部曲中文小说时,Qwen2.5-Turbo能够成功用英文概括每部小说的情节,这种能力是否让你心动?
体验与未来展望
如果你对Qwen2.5-Turbo感兴趣,可以通过阿里云模型工作室的API服务、HuggingFace Demo或ModelScope Demo来亲身体验其强大功能。阿里云也表示,将继续优化该模型,提高其在长序列任务中的人类偏好对齐,并进一步提升推理效率。同时,他们计划推出更大更强的长上下文模型。
相关链接
官方介绍:https://qwenlm.github.io/blog/qwen2.5-turbo/
在线演示:
https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
https://www.modelscope.cn/studios/Qwen/Qwen2.5-Turbo-1M-Demo
API文档:https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen









暂无评论内容